Hi guys! I’m starting to work on a Bengali font and thought I’d start a thread so we can work through issues that might pop up during the development. (Is this a good idea? I can do this privately if you like)
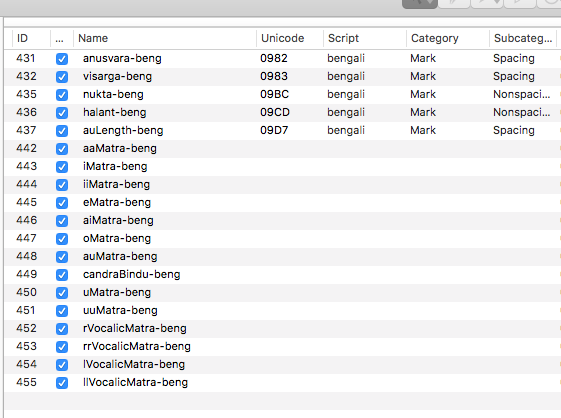
I populated the character set based on the glyph lists in the menu, but some of the unicode values are wrong (all of the vowel matras). I will change them manually, but wanted you to know. It also looks like the GlyphData.xml file hasn’t been updated to reflect the -beng naming scheme. (names are listed as “abengali” “aabengali” “aavowelsignbengali” etc.)
A thought: have I maybe messed up my GlyphData.xml file? I tried to “roll my own” once and maybe I’ve somehow messed up the original one? This was in the directory that you listed in the tutorial.
It would be a great help to future users if the design and production process were written down and eventually turned into a tutorial similar to the one Mota Italic wrote for Devanagari.
Hi guys! Thanks – updating did fix those vowel names for me.
The Bengali character set looks incomplete (doesn’t have Reph? Or am I missing it?). Has someone actually created and finished a Bangla font using Glyphs? Will their character set and feature code make it into the program in the future? Or is this something you need me to help with?
Hi everyone,
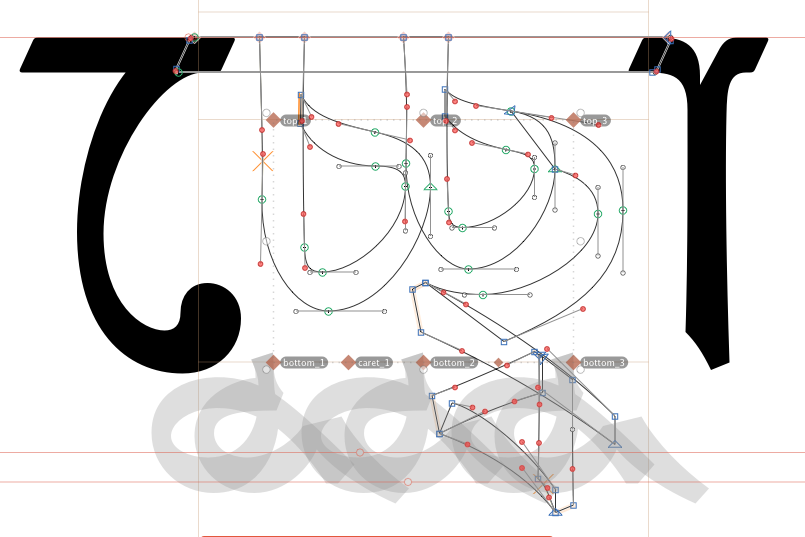
I am trying to understand why automatic caret anchors are generated while designing the conjunct characters. It is also showing multiple top and bottom anchors while generating the anchor marks for conjuncts. It would be great to have some feedback on this.
I have generated the list of characters from the “conjuncts” panel. I think it is generating the anchor marks and the carets based on the components of the conjuncts. The image attached above is called c_ch_ba-beng. So do we get rid of the multiple anchors and the carets individually? I also found a few conjunct glyphs which did not generate carets automatically, but had multiple anchor points.