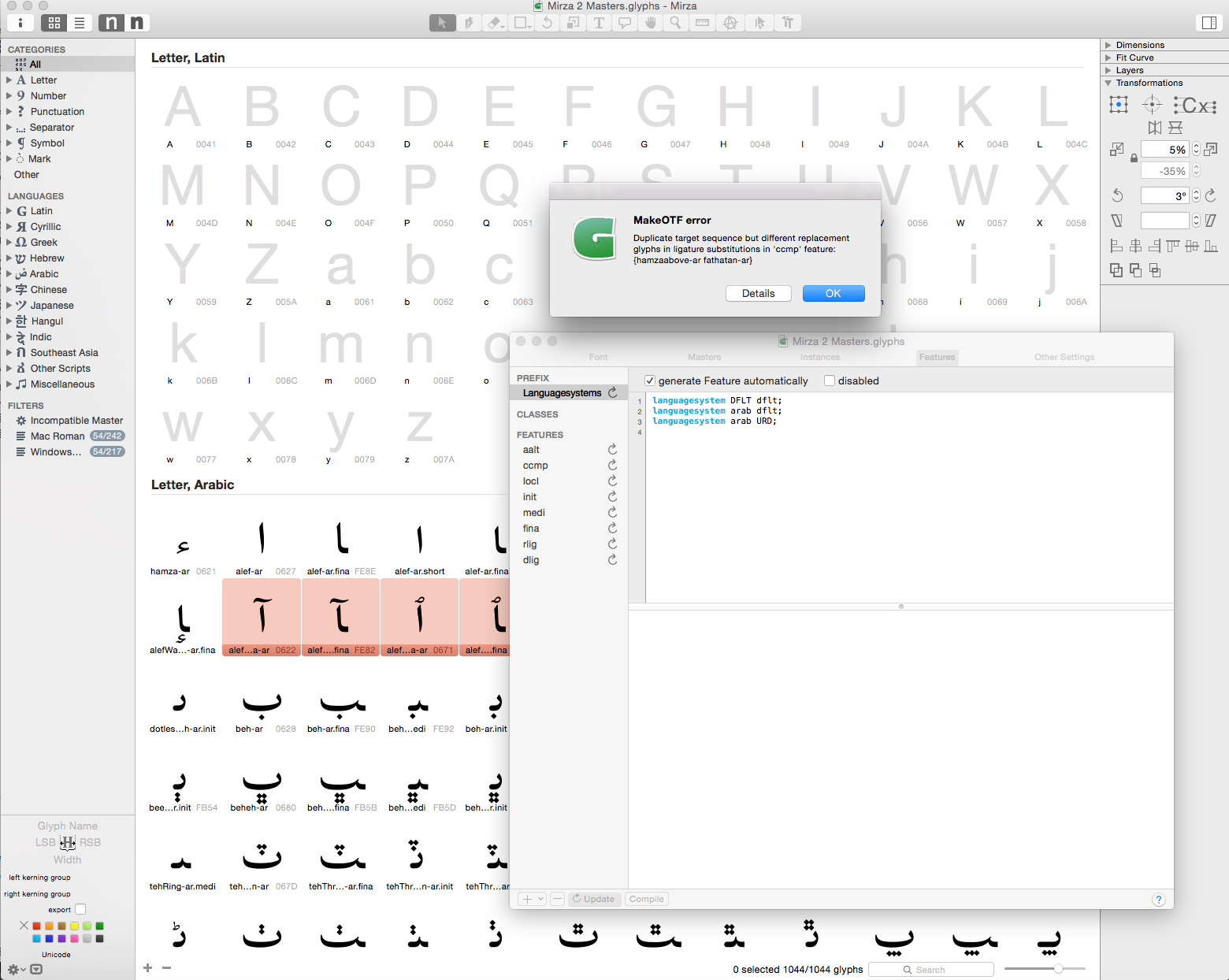
Then you have a two glyphs that are made from hamzaabove fathatan. You need to remove one of them.
Thanks! What is the common property? Name, unicode value?
Background: Kourosh tried to remove a duplicate glyph with the same name, but he still had this error. Thinking about this, is it possible that there may be a caching issue or something similar? I.e. should we try saving and then reopening the project?
This is what I did. But there is some letters decomposition that keep functioning without showing up. I had to discover it by accident when I opened the font with FontLab and saw the ccmp table.
I just did (I guess)! Let me know if you received it.
By ‘serious damage’ I guess I was more concerned about its ‘under cover’ operation! but even if I knew about those decompositions, there is an error that needs to be corrected. ‘Yeh with hamza above’ is decomposed to Yeh Farsi it seems, and hamza above. Since this is happening in ccmp, the whole Arabic substitution instructions for Yeh with hamza above is replaced by instructions for Yeh Farsi. Meaning the initial and medial forms have two dots below and of-course plus hamza which is placed on top on the fly. (not in the glyph but in text rendering because it is a decomposed mark that come after Persian yeh)
Yeh with hamza above doesn’t have any dots below in any of its presentation forms.
Which decomposition is there that is not in ccmp? Can you give me one example, please?
I could not see any deviances with the file you sent me in Glyphs 2.4.2 (1060) on macOS 10.12.6. I get the same substitutions that were in the ccmp, some of them reordered.
Again, I cannot reproduce this with the automated ccmp.
Can you describe steps how you achieve this decomposition? Where are you seeing it?
Terribly sorry. This seems to be my own doing! There is no undercover activity. Perhaps my own absentmindness!
Now I know how to fix that and it’s easy to do.
Okay there was another ‘serious damage’ that I can fix it now but it’s not quite my own doing.
I think it is better to name ‘alef-ar.short’ and ‘alef-ar.fina.short’, respectively ‘alefshort-ar’ and ‘alefshort-ar.fina’. This way it will be automatically included in the ‘fina’ list of Arabic contextualization and it is less complicated to write variants of alef in the context (such as in lam-alef composition) without adverse effect.
Have you tried: alef-ar.short and alef-ar.short.fina, and make sure the feature that substitutes the alef for its short version comes before the positional features.