Hello there,
I used the recent cutting edge versions. 2.4.2(1045)
Recently, tested it interestingly because there is a Hangul update.
I tried to report cid ROS mapping bug, but it seems to be late.
However, there are bugs that have not been fixed yet.
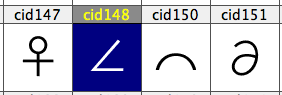
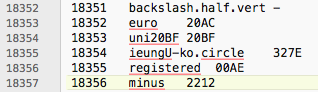
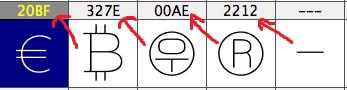
The problem is that the name of uni22A5 (cid149) does not match “nice name”.
Please refer to the image.
And, there is one thing that has not been solved for a long time.
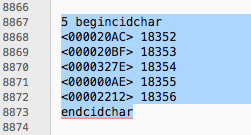
The recommended hangul CID mapping in ADOBE is from cid1 to (and .notdef) cid18351.
However, arbitrary characters that are not defined for some reason are mapped from cid18353.
Skip cid18352.
All I could do was to erase the ‘cid18351’ of the from ‘Glyphs Hangul cmap’.
Of course I know it 's not a good way.
What is the problem?
Is the Korean version of the menu currently in progress?
I was envious of the localization of Japanese glyphs menu.
But now i do not have to be envious.
It is recommended that some of the menus be written in English pronunciation and convey meaning.
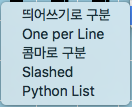
One per Line → 한 줄당 하나로 구분
Slashed → 슬래쉬로 구분
Python List → 파이썬 목록
Finally, the “Hangul Composition Groups” feature is amazing and incredible.
I know that it is not easy to understand and make a combination function of Hangul.
So many many thanks to the glyphs teams.
It seems that additional production of jomo can not be done at present.
Modern Hangul is not made with 3 sets (chosung 1 set, jungsung 1 set, jongsung 1 set).
‘E’ and ‘I’ in English are different from each other in the number of vertical and horizontal lines, the font quality will be higher because of various changes.
Therefore, the number of jamo can be 10 sets or 100 sets at the time of Hangul combination.
The number of jamo sets is changed case by case.
Should be able to distinguish between characters with ‘jongsung’ and ‘without jongsung’.
Because, can not share ‘chosung of ga-ko’ and ‘chosung of gag-ko’ combination elements.
I hope to build a system that can add them later.
How do share Combination elements(component) together?
I thought it would be a way to bind, but the glyphs were not exported.
So I made one per line, but I do not know what to do other than this.
Are there any examples or images to reference?
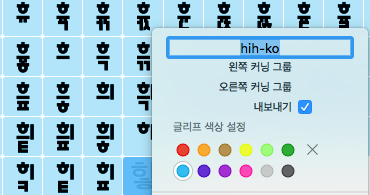
Due to a bug, one letter has not been exported. ‘hih-ko’
uptack is the proper nice name for uni22A5 and cid149. There is a AGL name perpendicular for that unicode but that is not in line width the other chars in that range and the unicode description.
If you have glyphs in the file that are not mentioned in the mapping file, Glyphs assigns CIDs higher than the last mapped CID. It doesn’t matter if there is a gap or not.
Why do you need to erase the entry from the CMAP?
The localisation is only partially done. If you like to help, I can send you the localisation files so that you could edit it yourself. I added the ones you suggested.
There will be more explanation, soon. Until then, I can assure you that it is possible to do everything needed to do all hangul syllables.
GeorgSeifert: uptack is the proper nice name for uni22A5 and cid149. There is a AGL name perpendicular for that unicode but that is not in line width the other chars in that range and the unicode description.
uni22A5 - uptack
uni27C2 - perpendicular
I Understand.
For some reason, my first work was ‘uni22A5’, but at some point I switched to ‘uni27C2’, so I thought perpendicular was correct.
GeorgSeifert: If you have glyphs in the file that are not mentioned in the mapping file, Glyphs assigns CIDs higher than the last mapped CID. It doesn’t matter if there is a gap or not.
Why do you need to erase the entry from the CMAP?
There are glyphs that do not appear in ‘Korean Standard Simbol’ but require code.
I want to create a mapping from cid18352 on these things.
Later, we will try to insert undefined characters such as opentype.
If you export the font, the glyph and code are pushed down one by one.
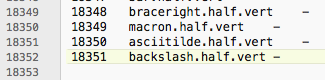
Cid18351 (vert glyph) was not included in the work
So I deleted cid13851 form Map File as a expedient and it was normal.
I want to allocate the unicode and cid number properly besides this, what should I do?
GeorgSeifert: The localisation is only partially done. If you like to help, I can send you the localisation files so that you could edit it yourself. I added the ones you suggested.
Thank you for trying to localize.
Later on we will provide more translations for localized menus.
If you are a .PO (Portable Object File) extension, I can help you translate.
The text file format is also not bad.
GeorgSeifert: There will be more explanation, soon. Until then, I can assure you that it is possible to do everything needed to do all hangul syllables.
I will wait for the day to fill the glass of beer.
Korea font foundry 80 ~ 90% uses fontlab program.
But I believe that I will be in reverse soon.
All letters, whether large or small, must be equal.
In the meantime, the font tools were centered in Latin.
Now that the glyphs seem to break the frame, I am grateful and feel good.
So we love glyphs.