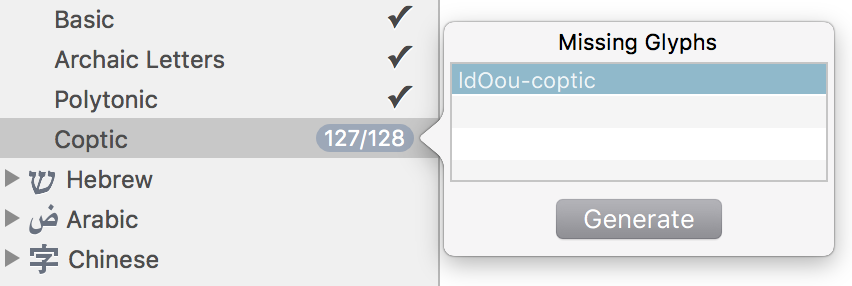
The predefined alphabet sets in Glyphs are great! Generating character slots and having them filled where possible for dozens of scripts, in one click, is fantastic.
However, for Coptic there’s a tiny typo in one glyph name, which keeps me from ticking off complete character coverage for Coptic (Glyphs.app v. 2.4.4 (1075)):
thanks for the report. I had a look at the Coptic glyph names and cleaned them up a bit more. I hope that it isn’t to disturbing. You need to run “Glyph Menu > Update Glyph Info” to get the new names (with the next update).
Hm, that’s quite some changes. Apart from the sort order, below is the diff (*).
If they’re both concise and sufficiently descriptive, I don’t care about the actual glyph names, though. (I like your convention that uppercase letter names are Capitalized, lowercase are not, additional descriptors are separated with CamelCase, and script namespaces are appended with a dash.) So, as long as my OpenType features won’t break, I conform to whatever is the Glyphs standard and will happily re-apply ‘Glyph > Update Glyph Info’.
Say I had oldAin-coptic, oldain-coptic (both assigned a Unicode codepoint value), but also oldAin-coptic.titl, oldain-coptic.sc and oldain-coptic.calt (none of which assigned a codepoint). When updating the glyph info, will Glyphs then also always update my customly affixed glyph names, along with any references thereof in the OpenType feature declarations, to the new AinOld-coptic, ainOld-coptic, AinOld-coptic.titl, ainOld-coptic.sc, and ainOld-coptic.calt? If so, I’m fine with blindly pulling any future updates. Nota bene, that I probably want Glyphs take care of generating my titl and smcp features automatically for me (based off the glyph name suffixes), while however curating calt manually myself.
I realize keeping glyph names of Unicode codepoint chars in sync with user defined salt glyhs may not be trivial, unless Glyphs would parse OT features, deriving a relational model between glyphs, and from that graph orchestrate the glyph info update procedure. For what it’s worth, I had been assuming Glyphs would standardize on Adobe glyph names, and/or default to some deterministic glyph naming/slugging function based off the Unicode character name. That way, glyph names would be more immutable/persistent reducing risk of breaking stuff.
Little addition: I just realized my proposal cited above (to use Unicode collation, cq. alphabetical sorting) indeed is very helpful to detect errors in glyph names and associated letter categories!
You now have i.a. dialectPni-coptic (Ⲻ uni2CBA) and dialectpni-coptic (ⲻ uni2CBB). From a numerically sorted list the error remains overlooked. But with alphabetical sorting
Unicode
glyph name
…
…
…
uni2C9A
Ⲛ
Ni-coptic
uni2C9B
ⲛ
ni-coptic
uni2CBA
Ⲻ
dialectPni-coptic
uni2CBB
ⲻ
dialectpni-coptic
…
…
…
it evidently appears that it should be NiDialectp-coptic and niDialectp-coptic instead.