You need to add a top mark in the caron. Or much better, use the caroncomb as a component in ccaron.
I guess I’m confused. If the caron is not typed or used, why do I need to place a top anchor on caron?
Do you think there is ‘character substitution’ going on with the apps (caron for caroncomb)? As a followup, any thoughts to why when I type caroncomb the first time a caron is produced, but the second time I type caroncomb a caroncomb is produced?
In order to maintain precise compatibility with Salish fonts from other sources, we can’t allow the users to type recomposed characters such as ccaron (U+010D) or scaron (U+0161). I haven’t yet removed them from my test font while I’m understanding some of the nuances. We need to maintain the individual unicode keystrokes for each glyph.
It seems that you have the precomposed ccaron in your text. And that inherits its top anchor from the c and not form the caron.
Does that mean the software application is by default substituting a precomposed ccaron when a c+caroncomb is typed?
If I use text inspector, and either type or copy/paste a c+caroncomb+commaabovecomb it appears there is substitution going on. In versions of my fonts 10 years ago I used CCMP features to sub all possible iterations (for instance a scaron or s+caroncomb) to a specific glyph (like this sub scaron by uni0073030C;). Is there a way, in the font features, to prevent substitution?
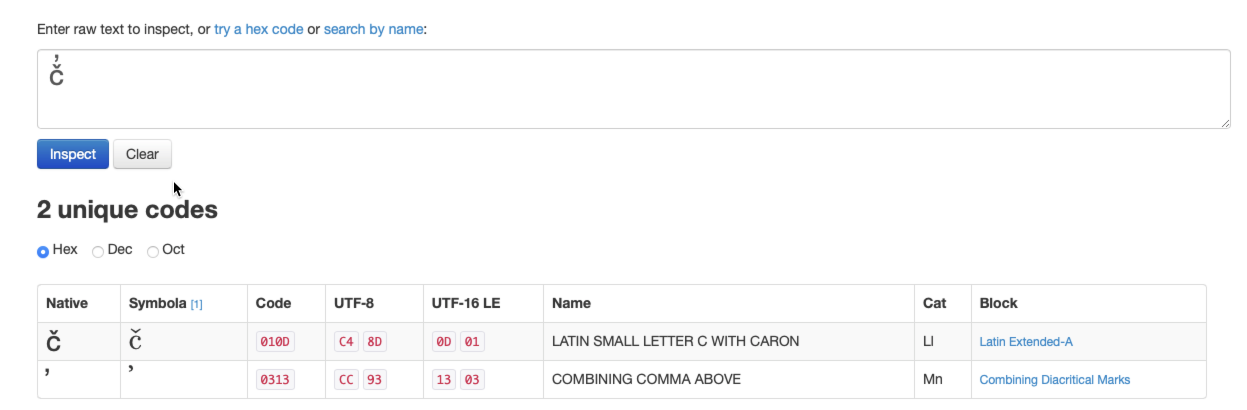
You can use the excellent FontGoggles to inspect the shaping of your text. Drag your font onto the window and type some text in the field at the top. The sidebar to the left shows you both the Unicode characters you entered as well as the glyphs as selected by the shaping engine (HarfBuzz by default).
Note that entering composite characters in multiple steps (for example by first pressing the combining ˇ where you get the yellow background or an underline and then enter the base character) may insert only one Unicode character. This is handled by the operating system.
Typically you don’t want to prevent the composition of glyphs and instead make sure your anchors are in all relevant glyphs. If that does not work for your specific case then you can decompose glyphs in ccmp.
Indesign is always using precomposed characters. This can’t be debugged with fontGoogle.
Thanks for helping me get my mind re-oriented. I used FontGoggles and this is what I see. What I’m particularly interested in is what unicode characters are actually stored in a document when it is saved:
- This: U+0063 U+030C U+0313
- Or this: ccaron (U+010D) and uni0313 (U+0313)
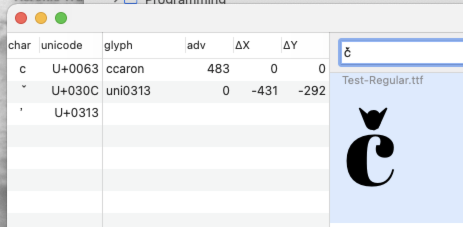
In other words, is substitution of a ccaron just for display purposes, or does it actually save the ccaron into the source document? The very fine point is that if one app saves separate unicodes for c+caron and another saves it as ccaron, then there is the potential for document exchange issues if all the fonts used do not support the features. Hope that makes sense, as some users have reported document exchange issues. I don’t know if the exchange problems are related to feature support (or marks) or a deeper issue with how different apps actually save the characters.
Typically some normalization and character composition is applied when storing documents. It may also depend on the input method, since entering /c and /caron may appear as two separate actions while in reality the operating system inserts just a single, precomposed character.
The left column (char, unicode) in FontGoggles shows you what you entered (and what macOS might have done with your input) while the right column (glyph, adv, …) shows which glyphs the shaping engine picked to display the text. In you screenshot above you can see that HarfBuzz combined /c and /caroncomb to a single /ccaron.
You can not rely on an application performing or not performing such normalizations, which is why the anchors should be set for all relevant glyph. Then it should work in all apps (at least as good a possible, some apps may still do something wrong or incomplete).
@GeorgSeifert mentioned that
I don’t have InDesign, so you should test in it as well and use FontGoggles as a guiding tool, not as a definitive reference.
If I’m understanding what you’re explaining, then normalization may or may not happen when storing documents, depending upon the software application. In addition, the shaping engine may normalize two separate glyphs (such as c and caron to ccaron) without changing the stored code points.
As an example, when I copy/paste a c+caroncomb+commaabovecomb that was saved in either Mellel or Pages, I see this (which leads me to believe these two apps store the individual code points and do not normalize.)
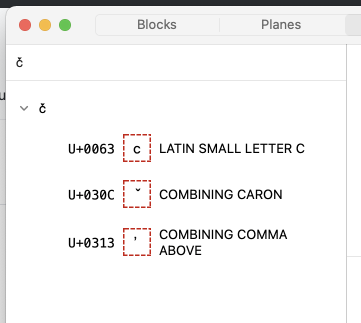
Is it possible, using OT Features, to transliterate (or I guess decompose or denormalize) and save a ccaron as c+caroncomb if a ccaron is found in a document? For instance, if someone inadvertently typed a ccaron (from a unicode picker app) instead of typing c+caroncomb. In the past I’ve created transliteration apps to do this, but that is somewhat complicated. I know it sounds a little crazy, just trying to dig into the nuances.
Not using fonts. Fonts are used to present text, they do not interact with the storage of text documents. This is what allows users to pick different fonts from the font menu; the text never changes, only its display.
Thanks for the clarification. As mentioned earlier some users create Salish documents using one unicode/opentype typeface/font. They send that document to another user, who doesn’t have the sender’s font installed, and the receiver applies what is supposed to be a compatible unicode/opentype font to the originating text. They say there are differences and incompatibilities. I’ve looked at the unicode code points for both fonts and they look compatible (with the exception that one of the fonts uses LIGA features to point c+caroncomb to a ccaron and then another LIGA to point ccaron+commaabovecomb to a PUA code point. Example:
- sub c caroncomb by ccaron;
- sub c caroncomb commaabovecomb by ccareje;
- sub ccaron commaabovecomb by ccareje;
where ccareje is 3 components at PUA U+F729 as in:
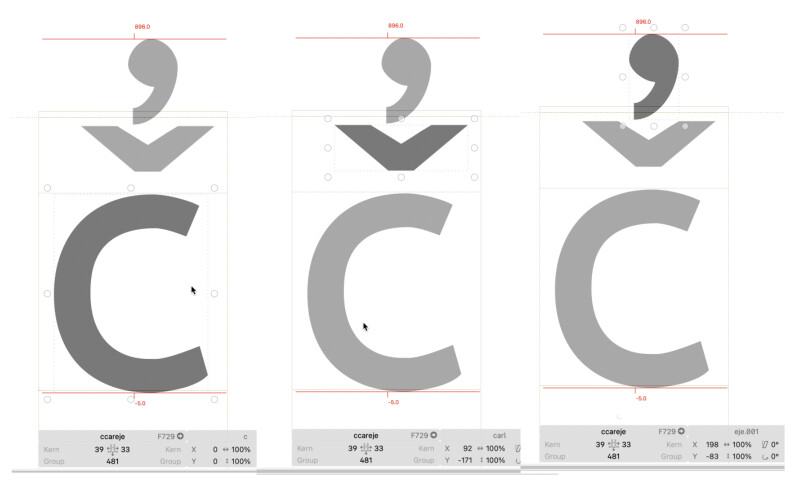
I don’t think this is the problem if, as you’ve explained, the PUA character is only used for the shape engine. Trying to brainstorm ideas, but it may be due to differences in versions of the apps generating and viewing the docs, where the apps have different support levels for various OpenType features.
You don’t need a c + caron + commaabovecomb glyph in your font. You need the three glyphs individually as well as ccaron (since it’s in Unicode).
Add the anchors to the right places and Glyphs automatically generates the required mark and mkmk code.
Here is a Test file and how it displays in FontGoggles:
Glyphs file: Test.glyphs, FontGoggles file: Test.gggls.zip
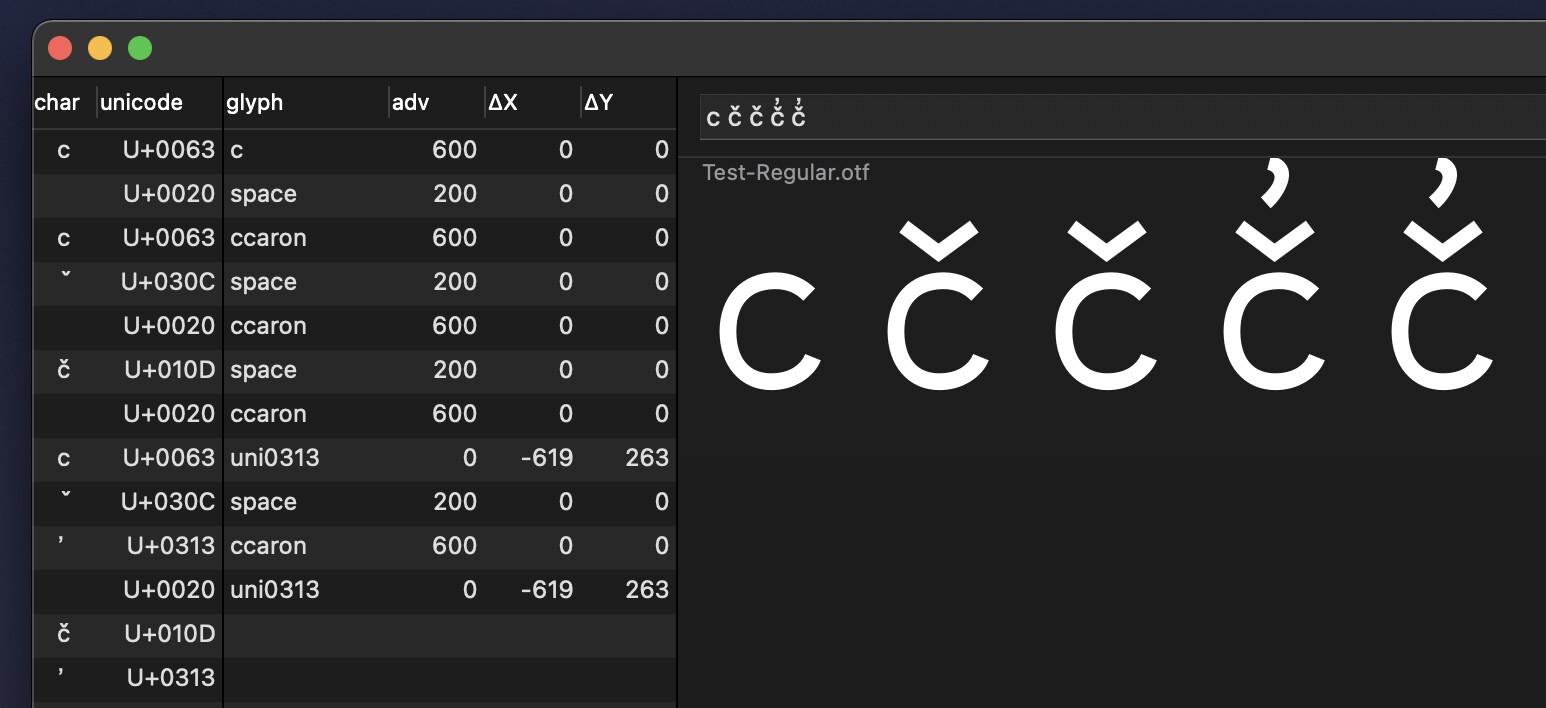
I don’t know about how Adobe’s or some other apps handle this. If you truly need to combine c + caron + commaabovecomb to a single glyph you can use the ccmp feature:
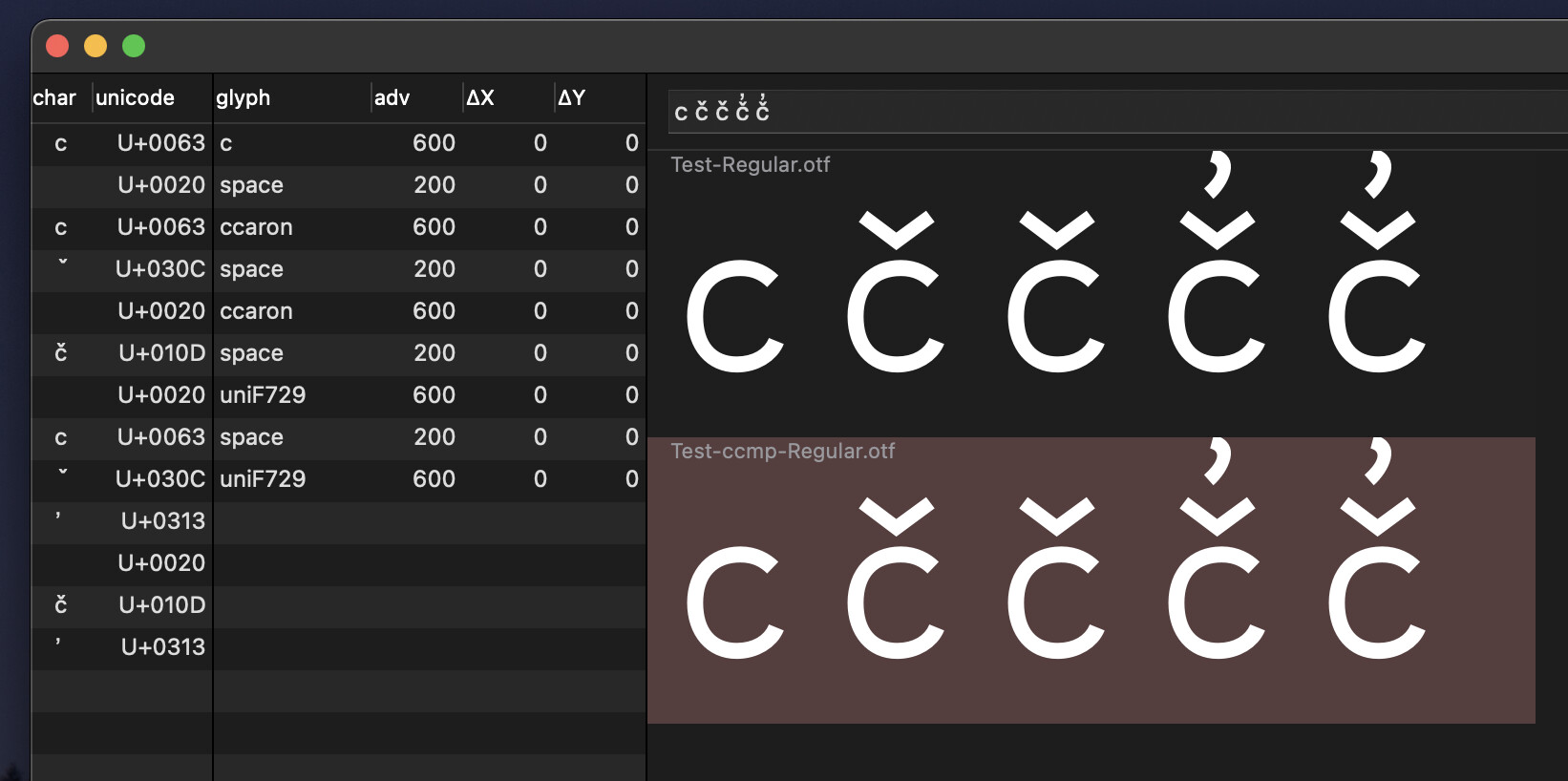
The ccmp code:
sub c caron commaabovecomb by ccareje;
sub ccaron commaabovecomb by ccareje;
And the test files from the second screenshot:
Glyphs: Test-ccmp.glyphs, FontGoggles: Test-ccmp.gggls.zip
Florian and others, thanks for the feedback. I think I have enough info to move forward, and I’ll stop peppering you guys with questions.
The examples I just sent you (ccaraje and PUA) were from another font developer where I can’t modify their font. I don’t use their features (LIGA and PUA). I don’t know whether what the other font developer is doing with OpenType is causing the document exchange problems the users are experiencing. I don’t want to use the other font developers features in the font I’m creating as they will probably cause incompatibilities. I’ll move forward with the suggestions you’ve provided and explain “this is what the experts are saying.”
If the font is substituting to a PUA glyph, the underlying text is not changed. If there is a PUA code in the text, it came from somewhere else.
I know Georg and Rainer disagree with me, but my approach is to put all the anchors at some round number like y=500. That way you can have the same height in all masters and not have to remember different values for different masters. Even better, you can have the same anchor height for all scripts even if the x-height/body height is different. That’s essential if you want marks from different scripts to sit correctly on a common character like dottedCircle.