Monotype Font Platform generate sample text automatically based on scripts supported in the font, however the result is not really predictable. I’m trying to figure out if I can control it or not.
Here are a few examples of the font file that contains multiple scripts, and in which language the sample text is generated by Monotype Font Platform:
Latin + Greek + Cyrillic + Mkhedruli + Hebrew + Arabic = Georgian
Latin + Greek + Cyrillic + Mkhedruli + Armenian + Hebrew + Arabic = Armenian
I don’t think that they checking the languagesystem tags because I didn’t have any features for Armenian or Georgian. Most likely they just check if some specific glyphs are presented, but I’m not sure about it. I made a request to their support and here’s a fragments from the answer:
Sample string is automatically generated by our system based on the metadata within the font file.
…
The current system behavior prioritizes showcasing distinctive features—particularly in non-Latin scripts—since the platform hosts a large number of Latin fonts and comparatively fewer non-Latin ones.
…
As a temporary solution, you may consider adjusting the font file metadata to make the English language settings more dominant. This may prompt the system to generate the render string in English instead.
I don’t get this logic about preferring non-Latin scripts. From a user perspective, if I see sample text in Armenian, I may think that the font is Armenian-only. So what the point?
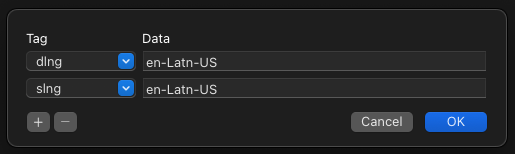
Anyway, I wonder what the “font file metadata” they may referencing to. I tried to add the Sample Text string as Default / English but it makes no effect.
Has anyone encountered this, and is it possible to control it?
I tried different options like “Latn” and “en-Latn-US” but it makes no difference on FontPlatform and the sample text still being in Armenian. Perhaps I should write back to them again and ask for a more information.
It might be checking OS/2 UnicodeRange bits. Try setting unicodeRanges custom parameter manually and see if it changes anything. Be aware that removing a UnicodeRange from the font might make some Windows apps use a fallback font for characters in this range, so it might not be a viable solution anyway.
Hi Khaled, thanks for the idea. For a clear test I have added only 3 Latin entries and even after that FontPlatform/MyFonts still display Sample Text in Armenian/Hebrew.
Then it must be checking the cmap table coverage, which contradicts the suggestion you get, since cmap is not metadata nor something that can be adjusted as suggested.
The worst scenario I might imagine that they just checking the existence of language-related glyphs. Yes that’s opposite to what they saying, but there are two difference — when support answering and when the tech team answering. In this case, I wish to get an answer from the tech team, so I made a request.
I received a response from Monotype, but unfortunately, they didn’t provide anything specific or useful.
We already have highlighted this to our developer’s team, and they have confirmed that the render string is pulled out of the font file characterstics. I would recommend checking the info of font files and comparing the details of the font files that have no issues in the render string, and hopefully, this might help.