It seems that the sidebar indicates which glyphs are missing for a given language according to the glyph-naming scheme. For example it will note that a particular codepage is incomplete if the glyph Euro instead of euro is included in the font, or indeed that a font with a different naming scheme than Glyphs’ built in model has no Arabic glyphs even though the font has fully functional language support. This is quite misleading and at odds with a fundamental tenet of OpenType and Unicode, the character-glyph model.
I think it would make a lot more sense if the panel was checking Unicode coverage rather than glyph names, and indeed it should actually say that there are ‘Missing characters’, rather than ‘Missing Glyphs’ (although I understand that you didn’t want to miss-out on this prime product-placement opportunity…).
Titus, you can build your own sidebar entries. I did create a long list of groups I use in my workflow. It allows me to use my own preferred set of glyphs and for instance compare font glyph list with my Minimal Set. Nevertheless, I would be happy if I could create Unicode lists as well…
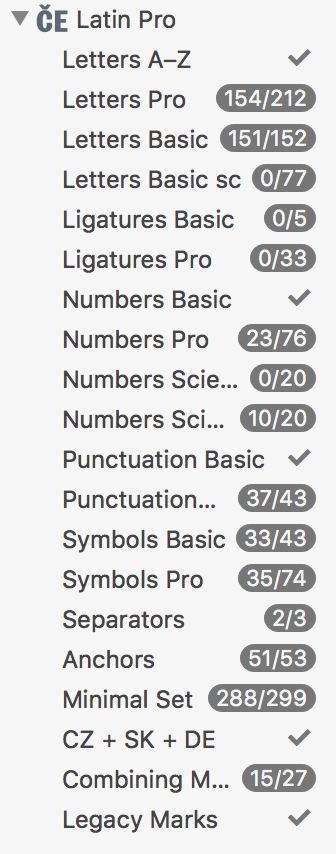
You can make your own list. The default lists (which you are not obliged to use) of course follow the default glyph naming scheme.
We are thinking about Unicode lists for a future version.
Since these entries are connected to the glyph names, it is really glyphs, not characters. By far not all entries have Unicode values. And it may be a bit of a philosophical discussion, but technically, a character per se cannot be missing. What can be missing is a glyph, with or without a reference to a character.
Filip,
thanks for your reply. You mean using list filters? That’s a work-around, but I would still maintain what I said in my original post: the in-built language sorting suggests to be something which it isn’t: an objective listing of the characters (and their names!) that you need to add in a font to cover a certain language.
Rainer,
I will refrain from posting observations in the future.
It is not a list filter, I’ve built custom sidebar entries following this tutorial: Custom sidebar entries in font view | Glyphs.
So I can for instance quickly check the language coverage of my fonts or quickly add missing letters for Catalan or Esperanto.
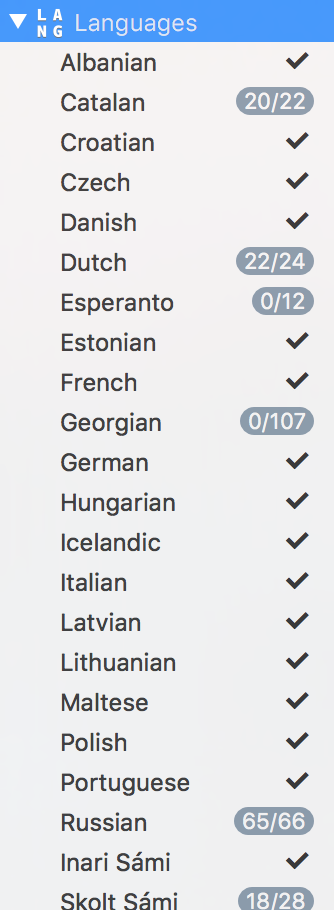
Filip, many thanks, I hadn’t seen this tutorial before!
That is one interesting gimmick, indeed. But I am curious:
Do you got reliable sources? While working on something related (proofing codepages and language coverage) I literally stumbled upon the very interesting and AFAIK most extended source/article about that issue by Underware. In a nutshell, it is unfortunately not that easy to just say this and that glyph is needed to make typesetting in one or another language complete. It turns out to be pretty hard to define a one and only glyph set for some languages. To be »better save than sorry« they decided to include usually unexpected coverage. A peek into the German reveals an inclusion of (Agrave,agrave,Eacute,eacute) which I as a mother tongue German speaker wouldn’t expect. Same is even true for English, … As I said: just curious.
Mark, you are right, it is not easy. I’ve been developing my list of accented characters for the last 15 years or so.
Compared to Underware, my approach is minimal or traditional. I intentionally ignoer letters used in foreign words, so I didn’t include ç in English because of façade or ü in Czech because of frequent surname Müller. It is just a tool, not a linguistic database.
I rather developed my own minimal set of glyphs covering most of the European languages, it is quite similar to the ranges covered by Latin-X by Hoefler or by OpenType Pro spec by Linotype. It should cover the majority of European languages using Latin script and therefore the loan words in English or German as well. On the other hand, I decided not to include Esperanto in my minimal set.
Sounds fair enough. Thank you for the insight @filipdesigniq
For the tools at Alphabet Type we rely strongly on data from Unicode’s CLDR project, which is also not a perfect solution, but gives a reasonably reliable basis for a lot of languages, sorting characters into required, auxiliary and punctuation categories.
Thanks Bene! I got this source also on my list. Good to know that you can confirm the utility of it 
Scriptsource by the SIL holds a lot of interesting information too, but I am not sure how easily accessible/scripable the data there is.