I’m creating an all-caps comics font, where you usually want to substitute the “I” noun with a crossbar-I. I don’t want the font to substitute all I’s (for example, within any word) with a crossbar-I, only the ones that have spaces on both sides of them.
How would I accomplish this? I know that one way would be to use the lower case i as the crossbar-I, but i’d rather make it easier for the letterer to just have it appear in this certain circumstance.
Well, in that case, do it the other way around. Make the crossbar version the standard and substitute it with the other I in the opposite circumstances.
The crossbar-I should present itself instead of the normal I in the following combos:
I
I’ve
I’m
As Georg wisely noted, I should also be replaced with crossbar-I in the following cases:
I.
I’ve.
I’m.
I,
I’ve,
I’m,
Even though I think these are rare situations.
I guess the answer would be to create a different calt feature for every one of these circumstances.
I tried creating a calt feature as you instructed but I keep getting an error message.
Please keep in mind that I’m a beginner-level user and haven’t done any programming or opentype coding perviously, so unfortunately you have to be very precise and ground-up with your instructions…
Where exactly should I place the calt feature? I know it’s not under dlig, as the ligature code.
is this all the code I need (for one substitution):
sub space i’ space by space crossbar_i space;
or should it be a longer form (found in adobe’s source):
feature calt {
sub space i’ space by space crossbar_i space;
} calt;
or something else?
Mekkablue: I’m not sure how that would work? I would still have to create conditions to the substitutions, only this time the other way around…
I guess the answer would be to create a different calt feature for every one of these circumstances.
You only need one feature, with a rule for each circumstance.
I tried creating a calt feature as you instructed but I keep getting an error message.
Post the error.
Where exactly should I place the calt feature? I know it’s not under dlig, as the ligature code.
CALT should be on its own, not inside of another feature.
When coding OT it helps to just add one line at a time and compile each one as you go. This is much faster than debugging once you have a hundred+ lines of code.
is this all the code I need (for one substitution):
Create a CALT feature in the feature editor and just paste in your substitution code. You don’t need to declare the beginning and end of each feature (feature calt {) in Glyphs, it does that for you.
you can only substitute one glyph by one other glyph. And if you use the context substitution (with the single quote) you can substitute the glyph that is marked with the quote.
So you write:
sub i’ quotesingle m by crossbar.i;
So you mark the i for substitution if it is before a quotesingle and a m.
Once again, thanks for the great advice. Feel like I’m starting to get the hang of this with your help.
I’ve created several ligatures now, which are replaced in situations where the crossbar.i is needed. The only situation I haven’t so far been able to figure out is when the noun “I” starts a sentence. Can you think of any way to detect whether or not there’s a glyph before it?
What do you want to do? This would substitute the I every time it follows another letter. This, I believe, was not the original purpose. What I suggested (and perhaps what you mean) is something like this:
lookup ISUB {
ignore sub @ALLGLYPHS I’, I’ @ALLGLYPHS;
sub I by I.crossbar;
} ISUB;
I put it inside a lookup, so the ignore line will not apply to anything that comes later. It may have a few other consequences though, so you may want to place it at the end of your feature. The solution assumes you have all relevant letters in a class called ALLGLYPHS. The ignore line means: ignore the case of a preceding letter, and ignore the case of a letter coming right after the I. But other than that, substitute every I by I.crossbar.
In a different aspect;
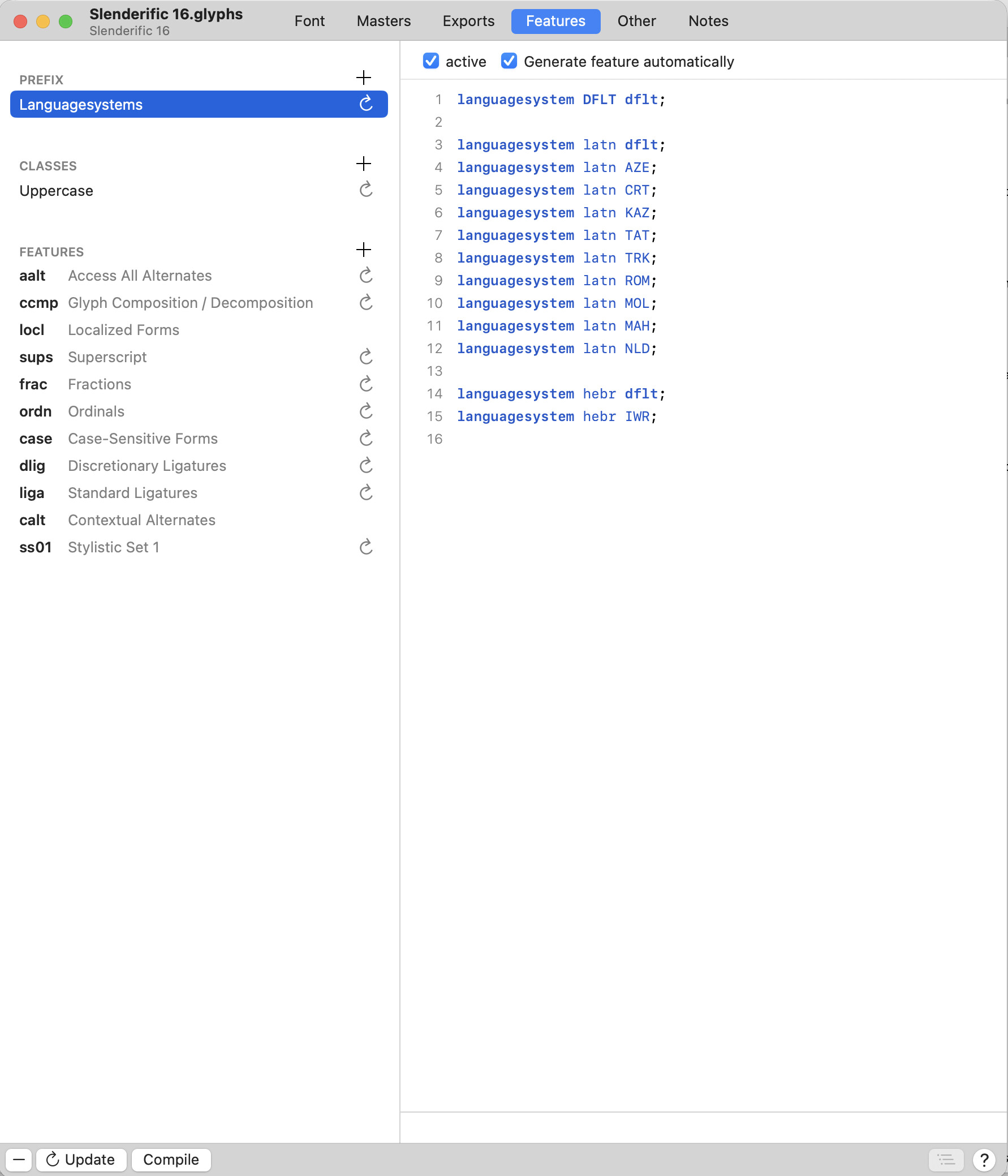
Wondering if it is possible to assign different {space}s for each script in a multi-script typeface?
i.e a Latin-Hebrew-Cyrillic would have two space at least?
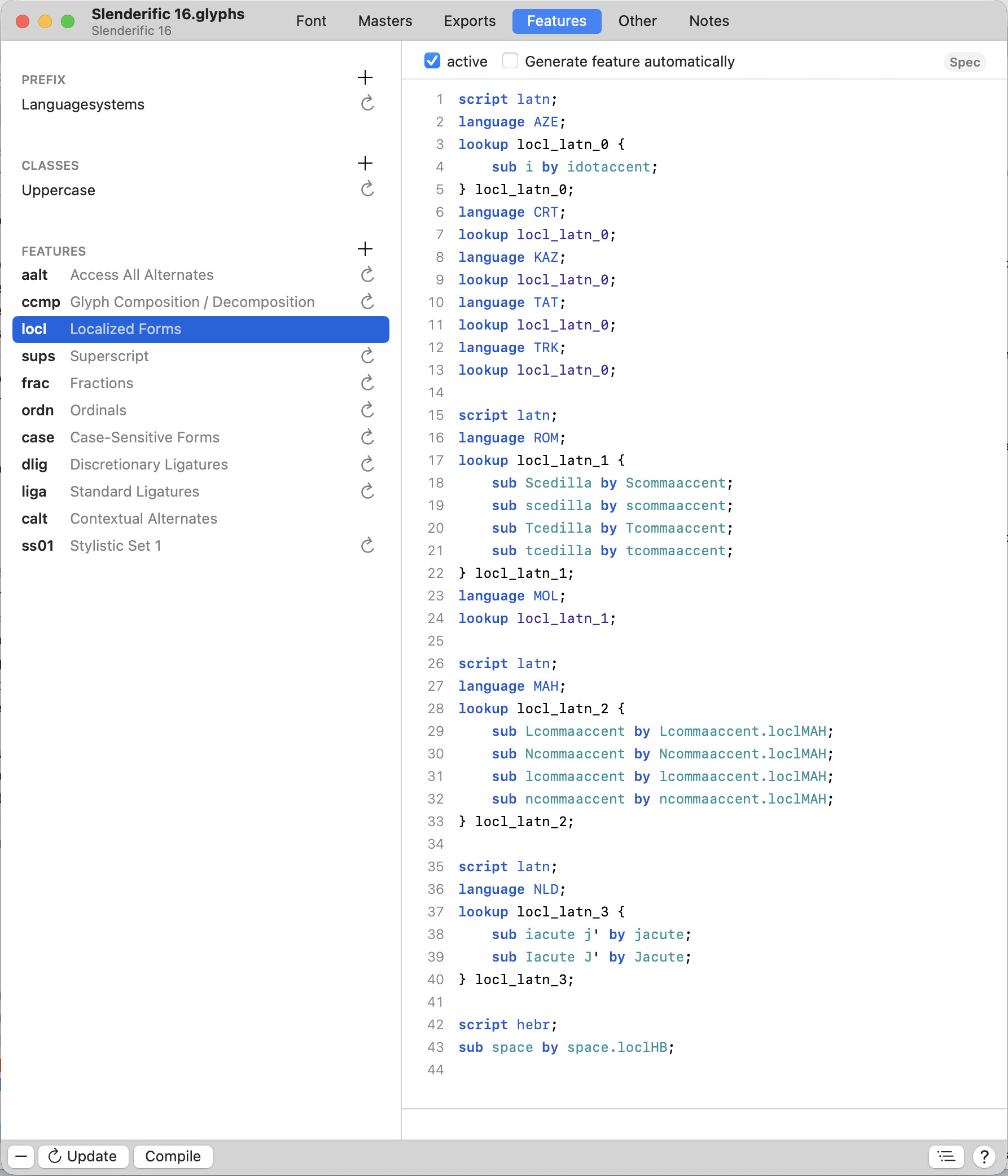
When I export the font, the substitution does not work (in InDesign with the Language set to Hebrew). If I assign the Language as any other than Hebrew, it works.
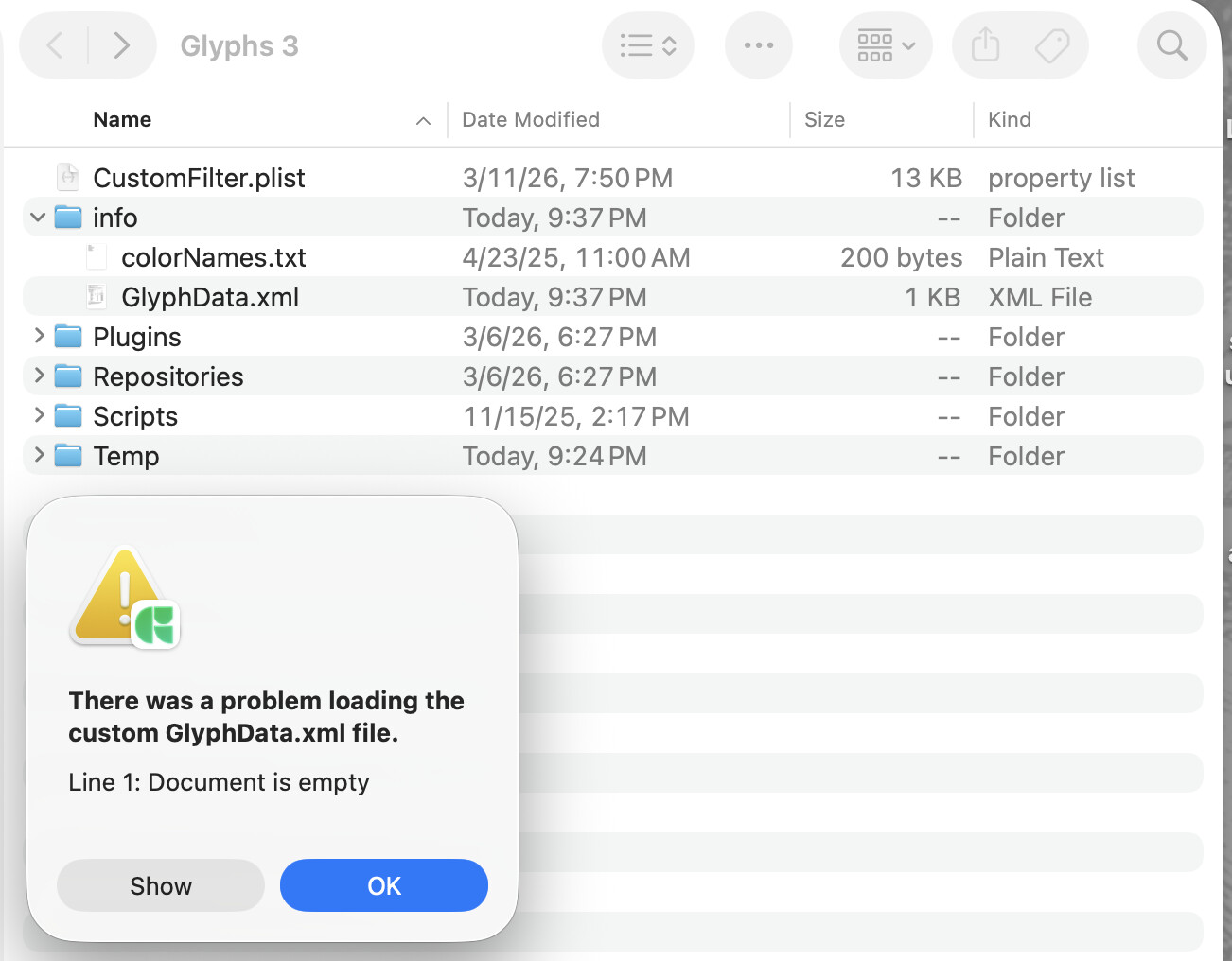
I tried making a secondary GlyphData.xml file, per the instructions ( Roll your own glyph data | Glyphs ). However, when I restart Glyphs, I get an error stating the custom file is empty.
The GlyphData.xml file needs to be a plain text file. Yours seems to be a formatted file. Do Format > Make plain text.
But, you don’t need the .xml file for what you are trying to do. You can just set the values directly (Edit > Info for Selection).
You should use space.loclIWR. Then automate the feature code.
BUT: substituting the space glyph doesn’t often work in Indesign. So test in FontGoggles to see if the OpenType works. If it then doesn’t work in Adobe apps, then you are out of luck.