background image for Kannada script is wrong in many places.
bhi-kannada(ಭಿ) vs bi-kannada (ಬಿ)
dhi-kannada(ಧಿ) vs di-kannada (ದಿ)
je-kannada(ಜೆ) vs ji-kannada (ಜಿ)
also with english names, I am afraid, I could get something wrong.
can I look at the feature file? or something to make accurate guessing?

I am pretty sure, these are all akhand + abvs features of
ಕ್ಷ ಕ್ಷಿ, … ಜ್ಞ, ಜ್ಞಾ, ಜ್ಞು,…
I am still afraid to take guess without some supporting reference.
Please assist.

The preview image is just what the system font gives for that combination. To render correctly, it might need more context or special markup. If you can give some examples (wrong preview and expected rendering) I can try to improve its.
The naming is based on the unicode names. If the name ends with an ‘a’ it is the full consonant. Without it, it is the ‘halfform’. Most of the glyphs you show above are precomposed glyphs. So ‘k_ssi-kannada’ is a combination of ‘ka-kannada+halant-kannada+ssa-kannada+iMatra-kannada’.
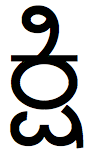
(And by making that screenshot I found my first example to fix).
1 Like

It is looking great. Thanks for quick response.
Few suggestions and some corrections.
fa-kannada ( ೞ ) is wrong naming in unicode. it should be llla-kannada (old kannada lla ). It was noted in unicode standard, they have put this in alias has Kannada Letter LLLA.
Also all its derivatives must be “lll” “lllaa” “llli” “lllu” llluu" “llle” “lllo” “lllau”
Infact, fa-kannada should be used for pha-kannada + nukta-kannada
j_nya-kannada should be ja-kannada+halant-kannada+nya-kannada (ಜ್ಞ)
k_ssa-kannada.base should be “k_ssa-kannada without the headstroke”. I am not sure, if it is even needed.
Since,
k_ss-kannada “ka-kannada + halant-kannada + ssa-kannada + halant-kannada” ( ಕ್ಷ್ )
k_ssaa-kannada “ka-kannada + halant-kannada + ssa-kannada + aaMatra-kannada” ( ಕ್ಷಾ )
k_ssu-kannada “ka-kannada + halant-kannada + ssa-kannada + uMatra-kannada” ( ಕ್ಷು )
k_ssuu-kannada “ka-kannada + halant-kannada + ssa-kannada + uuMatra-kannada” ( ಕ್ಷೂ )
k_ssi-kannada “ka-kannada + halant-kannada + ssa-kannada + iMatra-kannada” ( ಕ್ಷಿ )
k_sse-kannada “ka-kannada + halant-kannada + ssa-kannada + eMatra-kannada” ( ಕ್ಷೆ )
k_sso-kannada “ka-kannada + halant-kannada + ssa-kannada + oMatra-kannada” ( ಕ್ಷೊ )
k_ssau-kannada “ka-kannada + halant-kannada + ssa-kannada + auMatra-kannada” ( ಕ್ಷೌ )
are precomposed with akhand feature.
We need the below pre-composed and emphasis to drop one of “uMatra” in the base letter before combining “oMatra-kannada”
yo-kannada, mo-kannada, jho-kannada

Above is normal practice in Kannada script. Fonts which are developed by designers unaware of the script is missing these nuances.
We could create a group to emphasize, that these are script restrictions or something on those lines.
Or make it in different color and add a note if possible.
I will make another detailed account of the script requirements.
1 Like
I have changed the ‘f’ names. Using the fa-kannada for something else will be confusing. We need to wait a bit until all sources are updated.
The preview can’t always reflect all conditions, so the .base shapes are most likely wrong. Could you give me an example string where hey might be used and how they should look?
For the more detailed information it would be best to write a tutorial that has all the information (like the one for Devanagari ).
Will do.
Please don’t compare or equate or relate any Indic script Kannada, Telugu, Tamil, Malayalam with Devanagari. It’s very offensive.
Instead of fa-kannada we can use pha-kannada.nukta for pha-kannada+nukta
no. All meaningful parts of the name need to be before the ‘-kannada’, so this would be ‘pha_nukta-kannada’.
1 Like
I received an update. In the release notes, it looked like fa-kannada was renamed to llla-kannada
But, we still see it as fa-kannada.
Select the fa-kannada glyph, then go to the menu Glyph > Update Glyph Info. That’ll update the name.
I added all glyphs for Kannada script

under Kannada script, we still have couple of glyphs not generated.
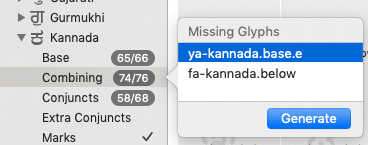
these two glyphs are still not added
ya-kannada.base.e
fa-kannada.below
If add the glyphs from languages->indic->kannada script-> its still names uni0CDE as “fa-kannada”
but llla-kannada.below is already added in the list.
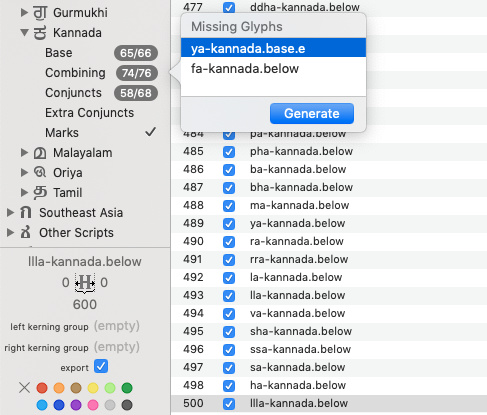
same with llla-kannada is already in the list but script filter is expecting fa-kannada to add
languages->indic->kannada script
and
window->glyph info
are not showing the same data
ya-kannada.base.e is not available from window->glyph info , filter → kannada
But ya-kannada.base is, and that suffices for the Glyph Info window. Not every dot variation is supposed to be in there, because it would be endless. That is because it is conceivable to do different dot variations. They would be inheriting the properties then.
The glyphs in the right hand side under language sidebar is not same as the “Glyph info” window for kannada script.
- fa-kannada was replaced to llla-kannada, but fa-kannada is still present in Kannada language sidebar
- ya-kannada.base.e is available from “Glyph Info”, but the same is not available in Language sidebar
Please explain more why it’s offensive.
Thanks for taking the time to explain all that. Very helpful. Best wishes.
1 Like